23-05-2025
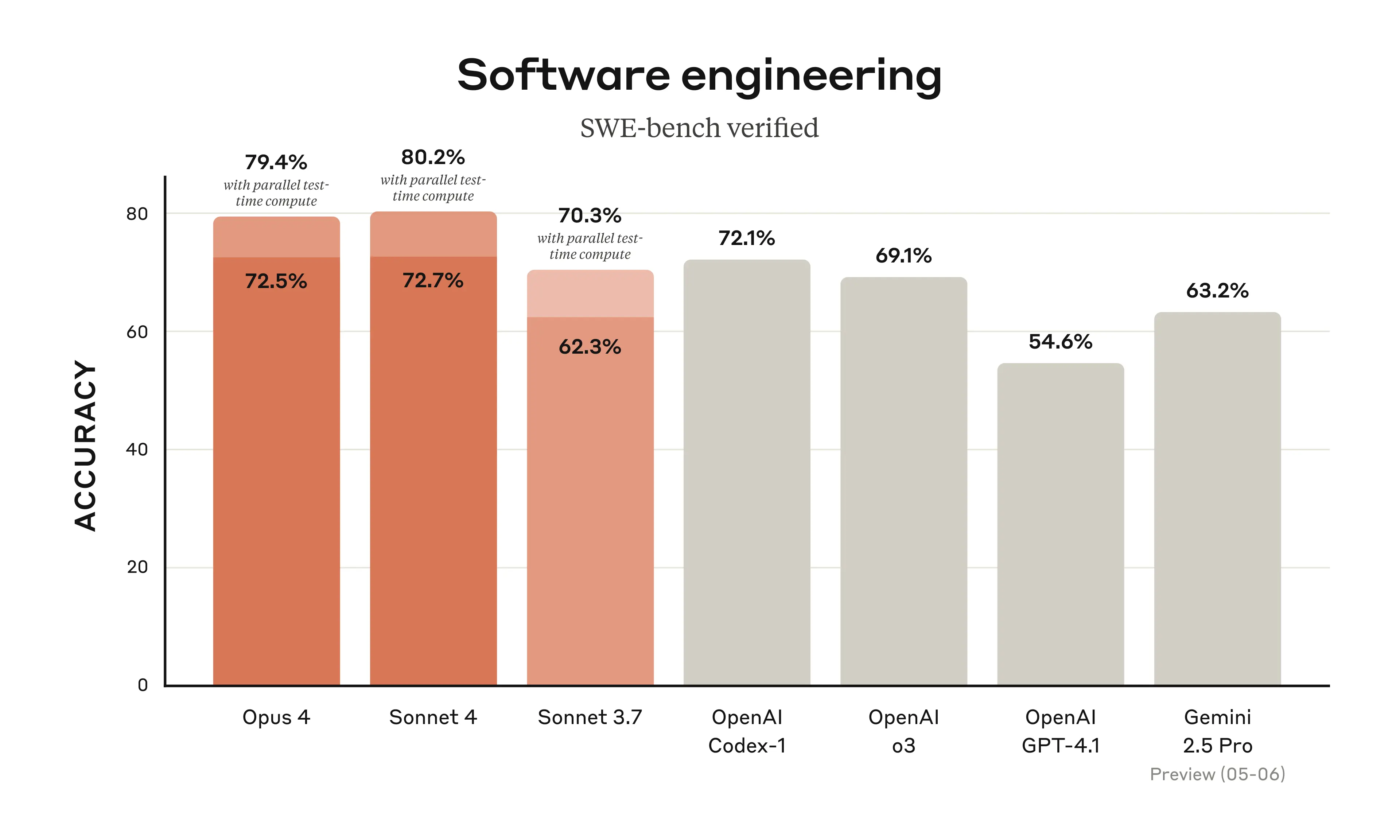
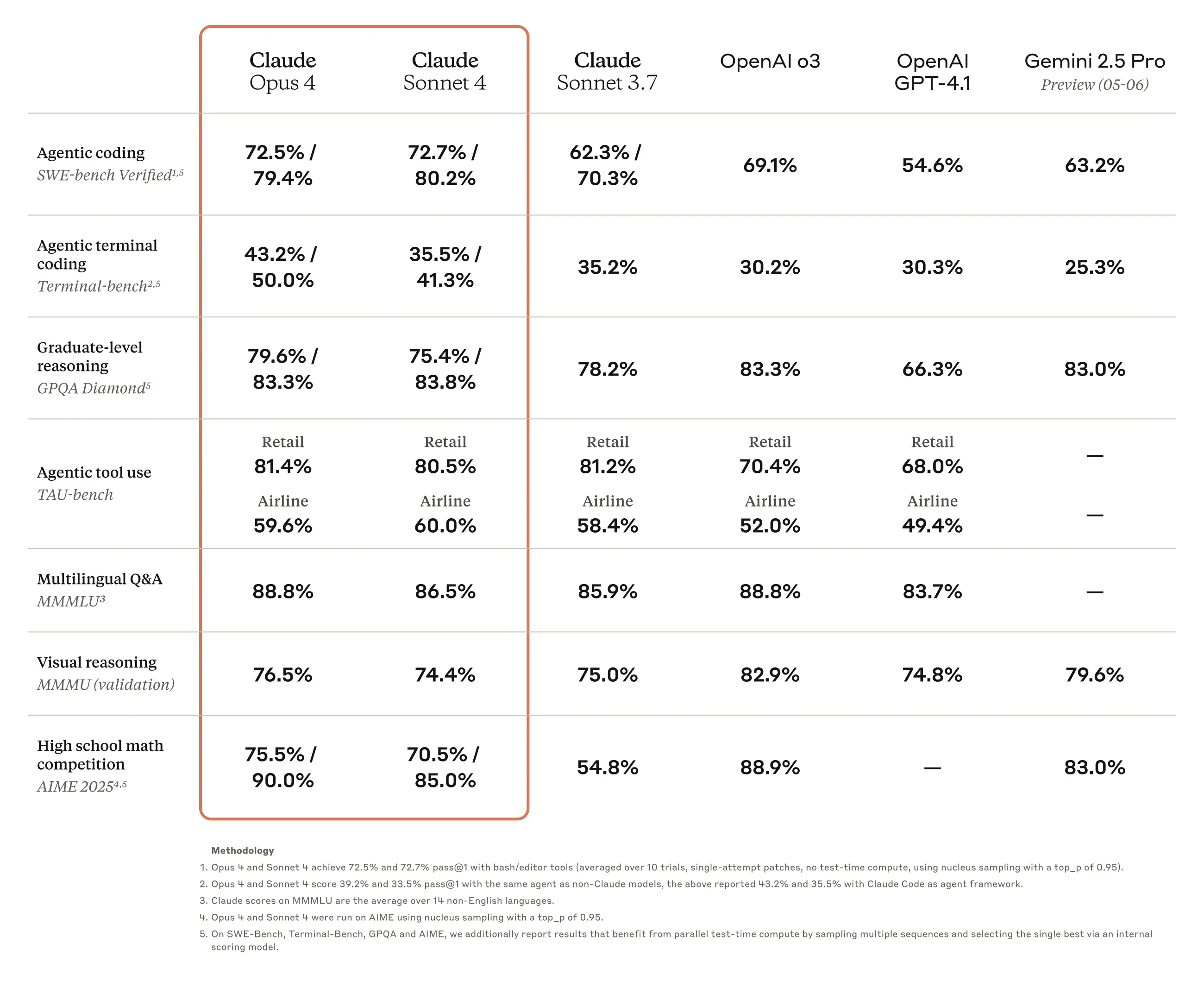
更新Claude 4 Sonnet, Opus
17-04-2025
更新o4-mini, o3
15-04-2025
更新GPT-4.1
28-02-2025
更新GPT-4.5 Research Preview
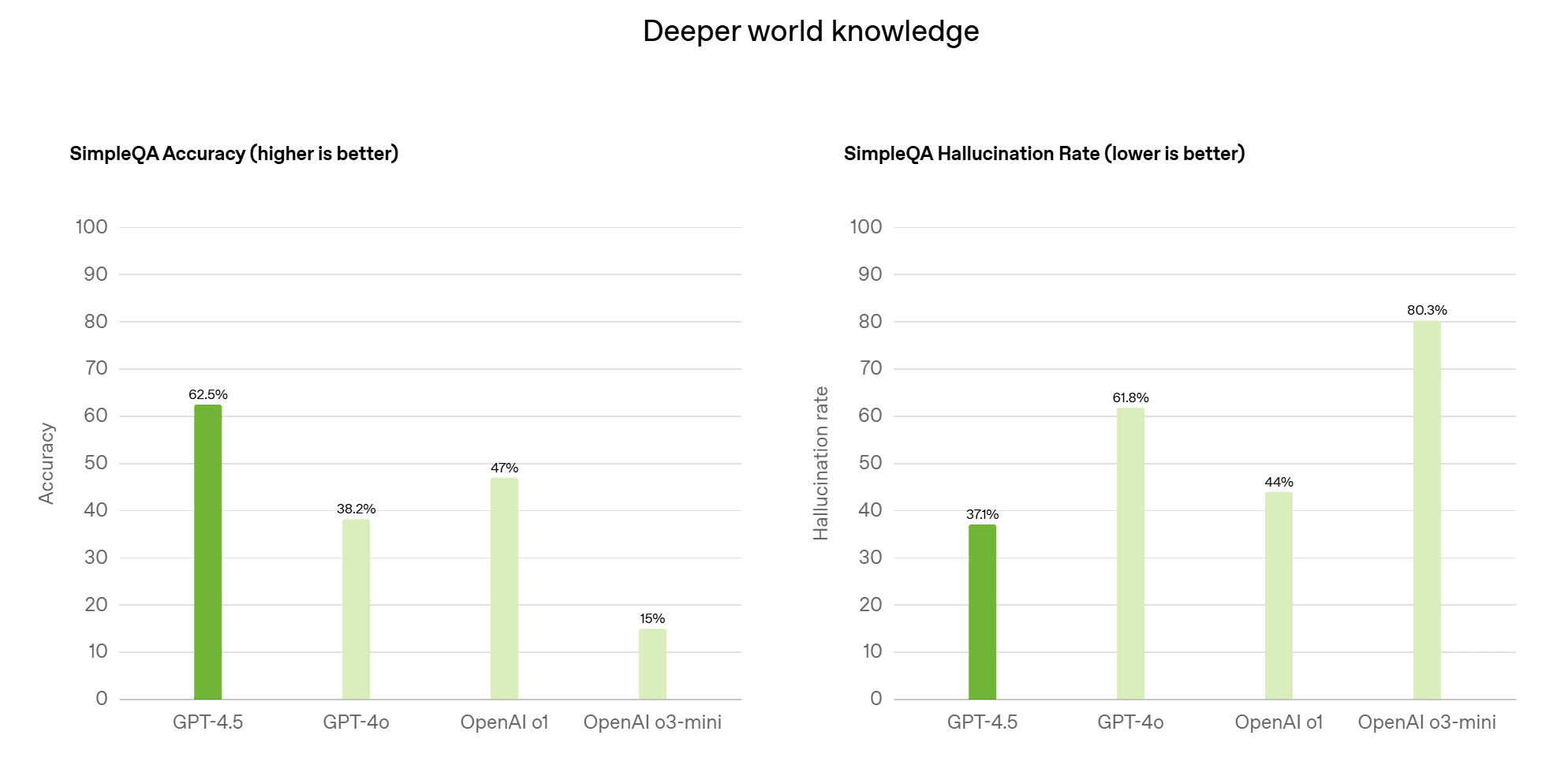
我們很高興宣布加入GPT-4.5 研究預覽版本 - 這是OpenAI 迄今為止規模最大、效能最佳的對話模型。GPT-4.5 在預訓練和後訓練方面都實現了重大突破。
通過擴展無監督學習的規模,GPT-4.5 提升了識別模式、建立關聯以及生成創意洞見的能力,無需依賴推理過程。 早期測試顯示,與 GPT-4.5 的互動體驗更加自然流暢。其更廣泛的知識庫、更準確地理解用戶意圖的能力,以及更高的「情商」,使其在改進寫作、程式設計和解決實際問題等任務上發揮更大效用。我們也預期它產生幻覺性內容的機率將大幅降低。
25-02-2025
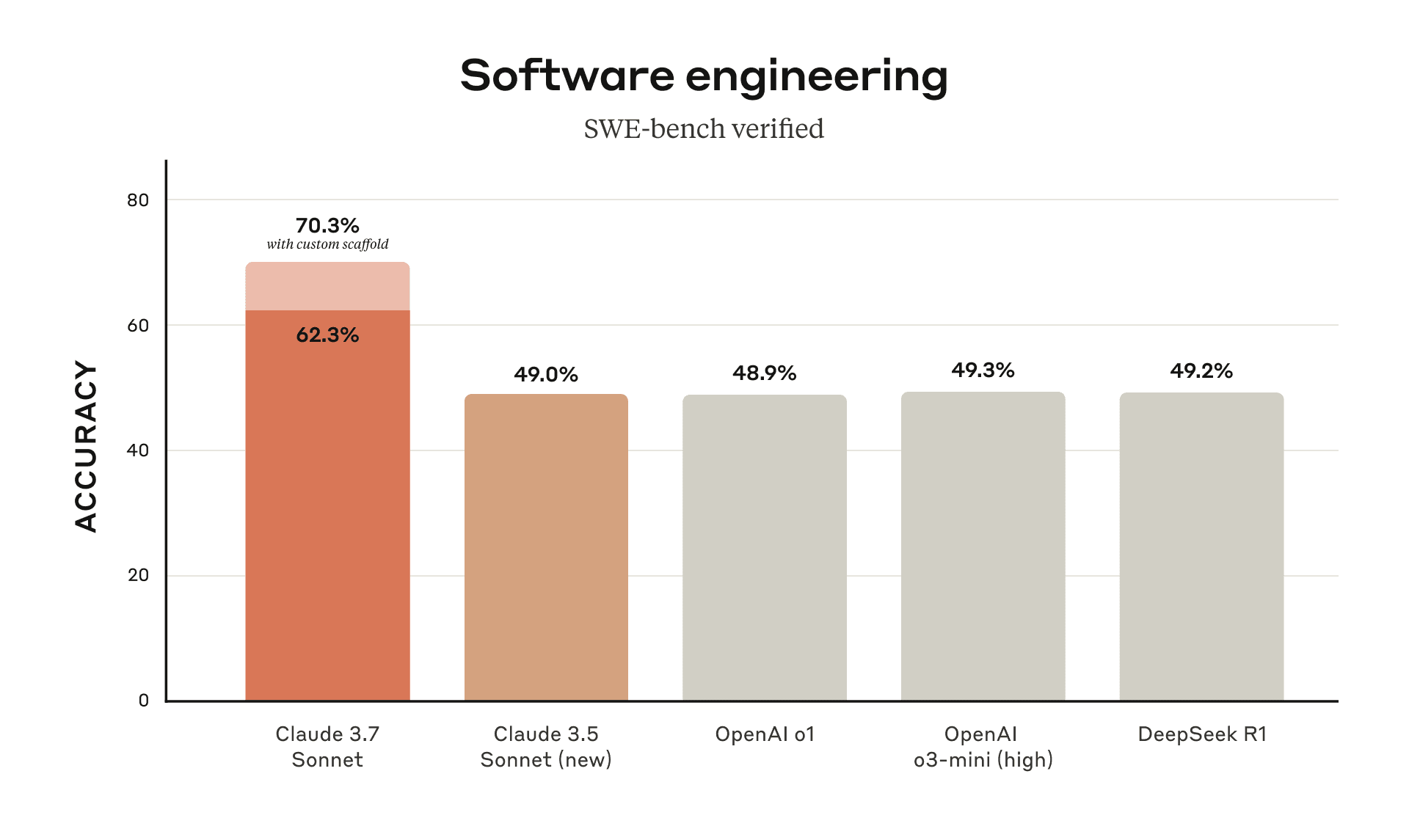
更新Anthropic Claude 3.7 Sonnet
Claude 3.7 Sonnet 現已在 GPTNow 上線
我們很榮幸地宣布,Claude 3.7 Sonnet 現已正式發布。這是 Anthropic 迄今為止最智能的模型,也是市場上首個混合推理模型。
主要特點:
• 支持即時回應及可視化的逐步思考過程
• API 用戶可精確控制模型的思考時間
• 程式編寫和前端網頁開發能力顯著提升
深度研究 Deep Research
我們很興奮地在GPTNow推出全新的深度研究 Deep Research功能,這是一項突破性的智能代理技術,能夠在網路上進行多步驟研究,解決複雜任務。
它能在幾十分鐘內完成人類需要數小時才能完成的工作。
深度研究是下一代獨立工作的智能代理: 只需提供研究主題 自動搜索和分析數百個在線資源 綜合整理出專業分析師級別的完整報告 這項革命性的功能將徹底改變我們進行研究的方式,為您節省寶貴的時間,同時提供深入、全面的分析結果。
01-02-2025
更新OpenAI o3-mini
OpenAI於2024年12月預覽並在今日正式發布全新的o3-mini模型。這是一款專注於推理能力的小型模型,具備以下特點:
- 在科學、數學和編程領域表現出色
- 維持較低成本和延遲
- 首次支持函數調用、結構化輸出等開發者功能
- 提供三種推理強度選項:低、中、高
與o1-mini相比,o3-mini錯誤率降低39%,性能提升明顯,特別適合STEM領域的應用。

21-01-2025
更新deepseek-reasoner
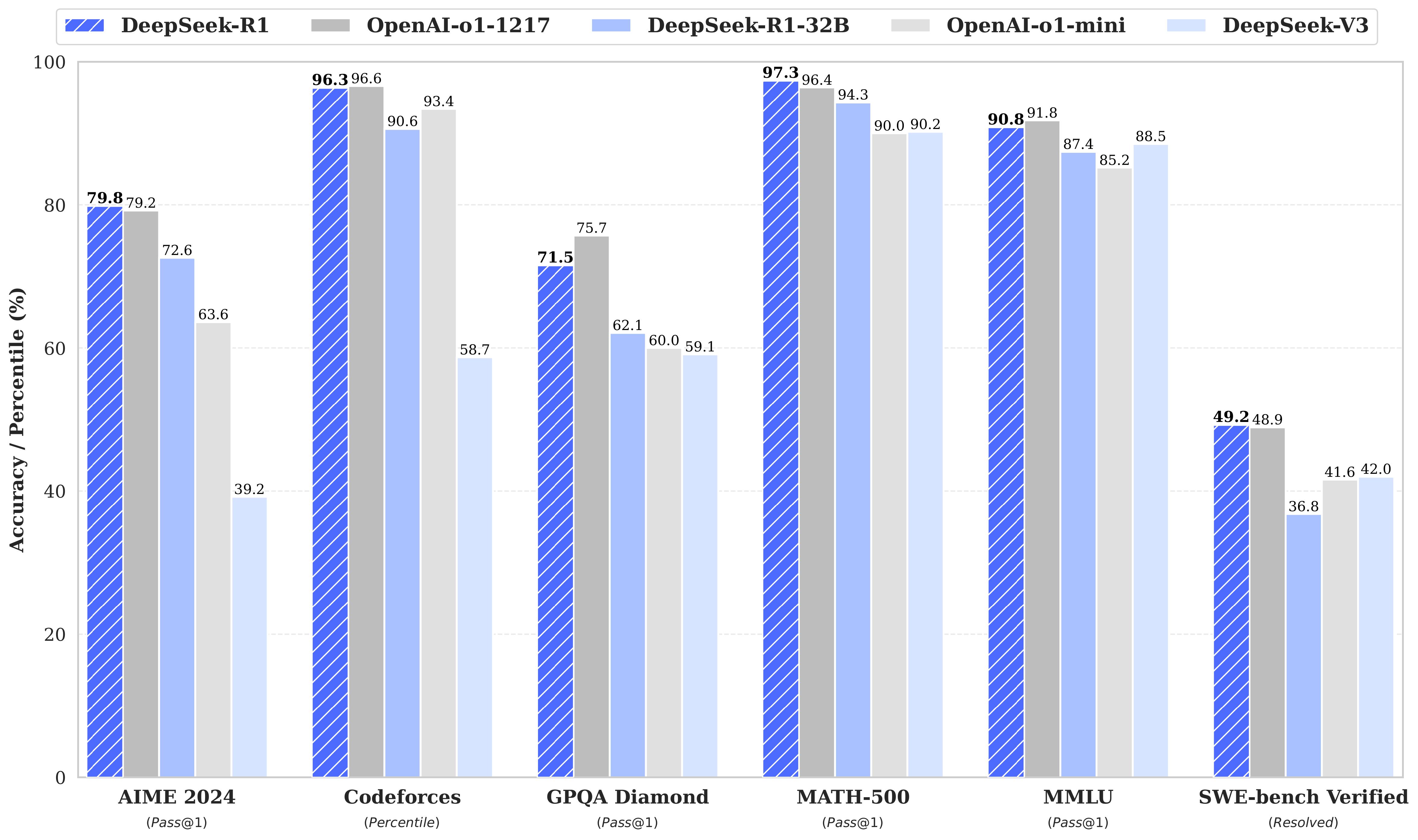
DeepSeek 推出了第一代推理模型:DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero是一個通過大規模強化學習(RL)訓練的模型,無需監督式微調(SFT)作為初步步驟,在推理方面展現出卓越的表現。通過強化學習,DeepSeek-R1-Zero自然地產生了許多強大且有趣的推理行為。然而,DeepSeek-R1-Zero面臨著無盡重複、可讀性差以及語言混雜等挑戰。為了解決這些問題並進一步提升推理性能,我們推出了DeepSeek-R1,該模型在強化學習之前加入了冷啟動數據。DeepSeek-R1在數學、程式碼和推理任務方面達到了與OpenAI-o1相當的性能。為了支持研究社群,我們開源了DeepSeek-R1-Zero、DeepSeek-R1,以及基於Llama和Qwen從DeepSeek-R1中提煉出的六個密集模型。其中,DeepSeek-R1-Distill-Qwen-32B在各種基準測試中的表現超越了OpenAI-o1-mini,為密集模型創造了新的最優水平。
20-12-2024
更新gemini-2.
Gemini 2.0 閃速思考模式是一個實驗性模型,經過訓練能夠在回應過程中產生模型的「思考過程」。因此,思考模式在回應時具有比基礎 Gemini 2.0 閃速模型更強的推理能力。

04-12-2024
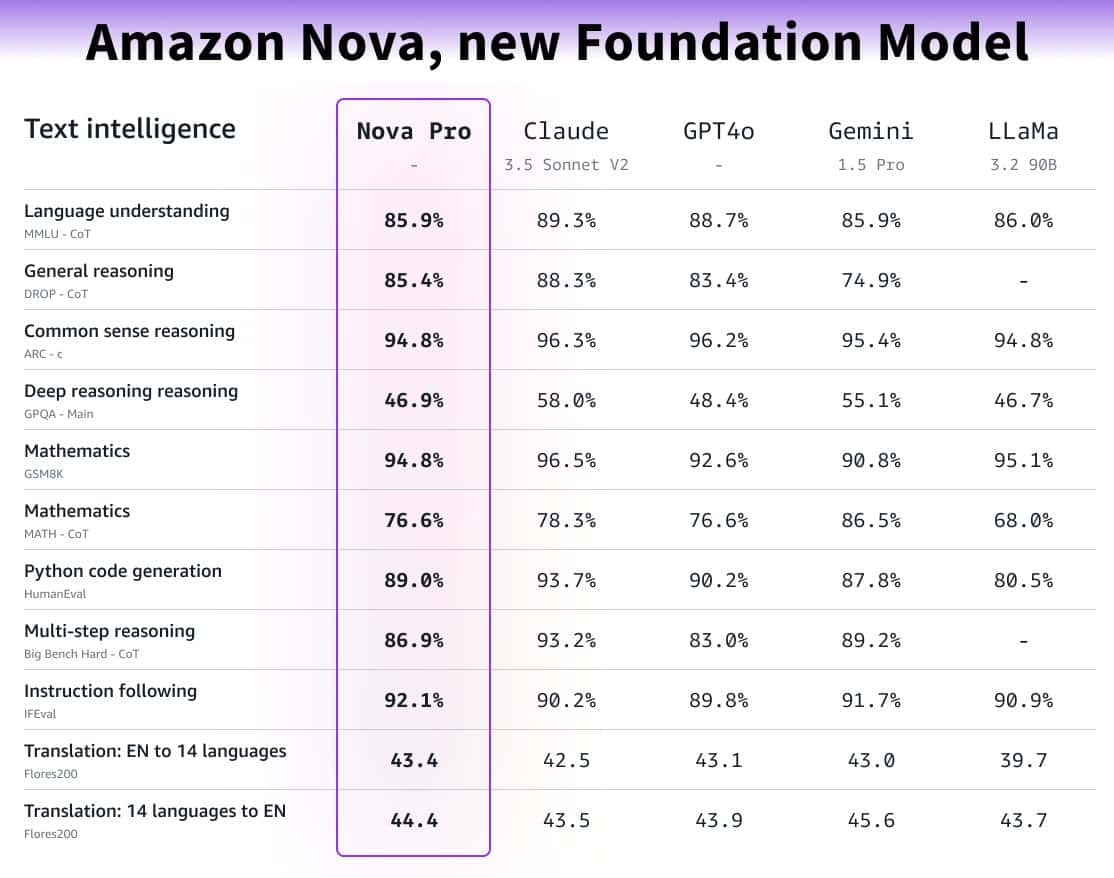
更新AWS Nova Micro, Lite and Pro
21-11-2024
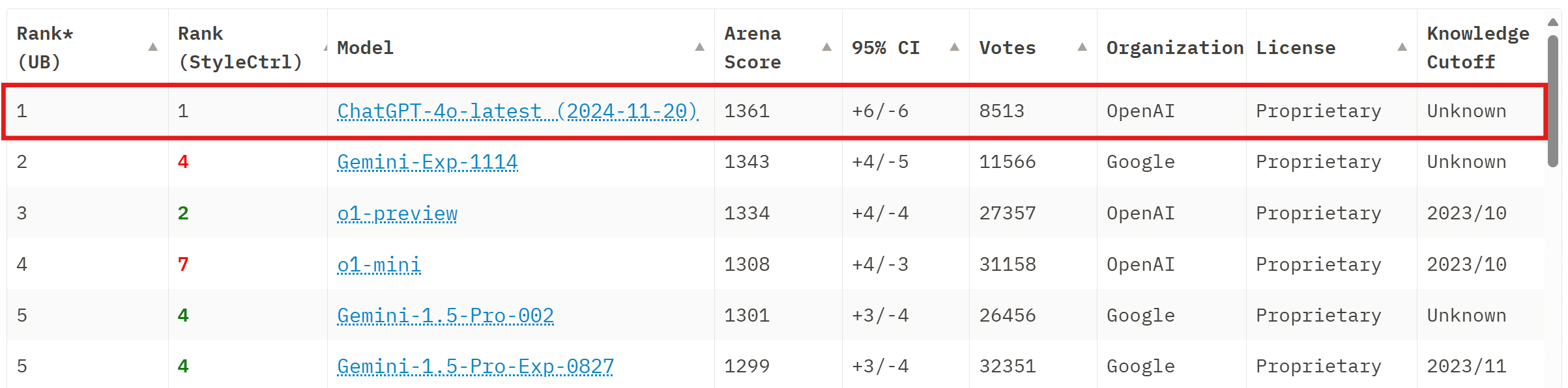
更新gpt-4o-2024-11-20
17-11-2024
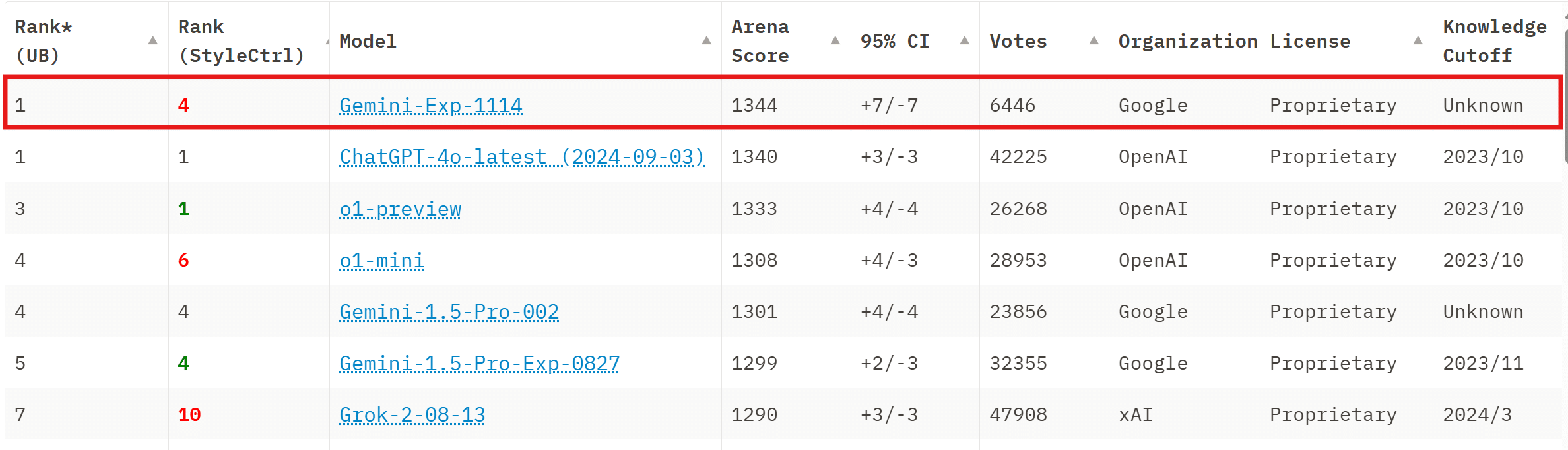
更新Google Gemini-Exp-1114
23-10-2024
更新Anthropic Claude 3.5 Sonnet
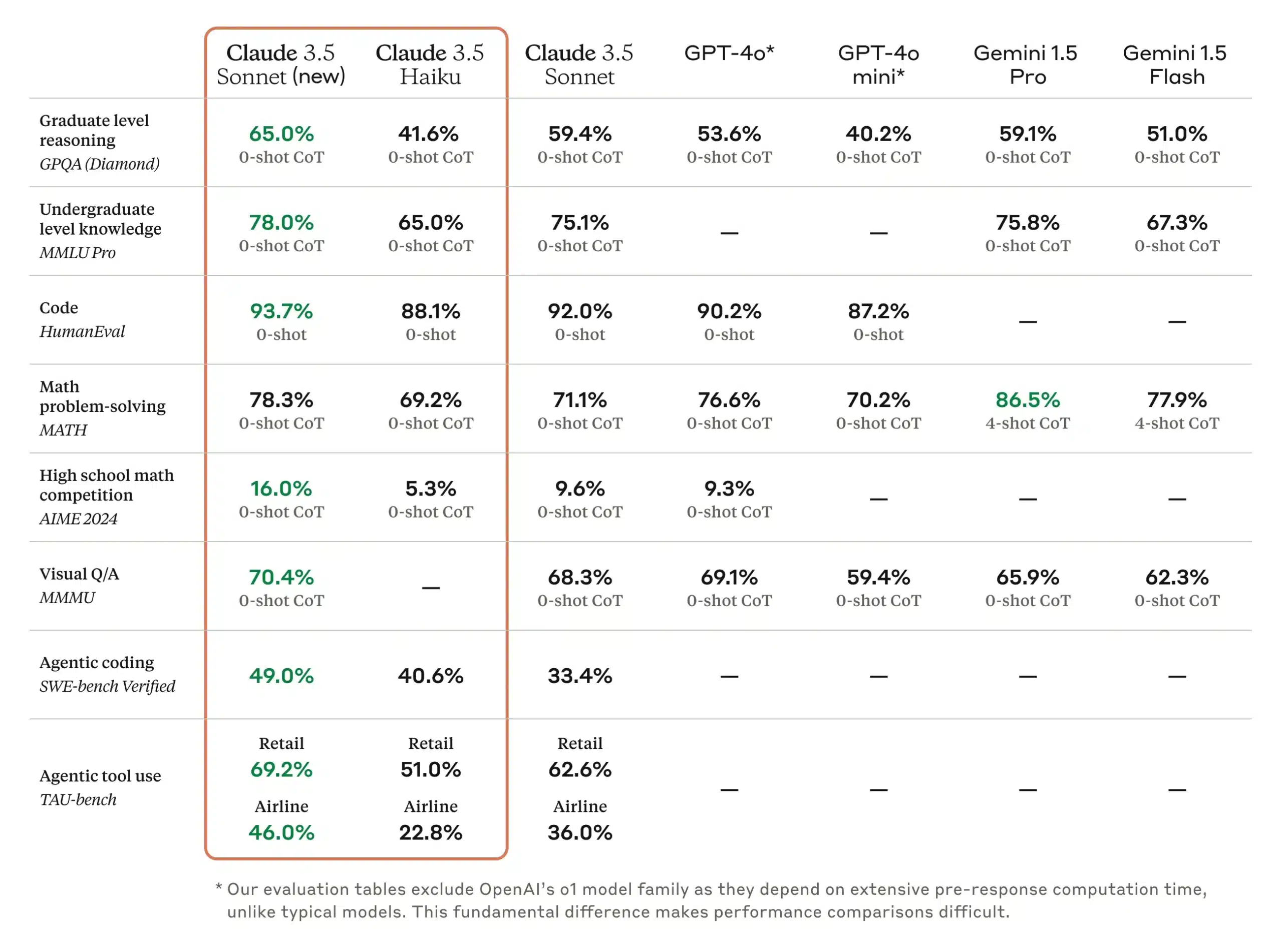
新版的 Claude 3.5 Sonnet 在業界基準測試中展現全面性的進步,特別在主動式編碼和工具使用任務方面有顯著提升。在編碼方面,它在 SWE-bench Verified 的表現從 33.4% 提升至 49.0%,超越所有公開可用的模型—包括 OpenAI o1-preview 等推理模型和專門設計用於主動式編碼的系統。在 TAU-bench(一項主動式工具使用任務)中,零售領域的表現從 62.6% 提升至 69.2%,在較具挑戰性的航空領域則從 36.0% 提升至 46.0%。新版 Claude 3.5 Sonnet 在維持與前代相同的價格和速度下,提供這些進階功能。
早期客戶反饋顯示,升級後的 Claude 3.5 Sonnet 在 AI 輔助編碼方面取得重大突破。GitLab 在測試該模型的 DevSecOps 任務時發現,它在不增加延遲的情況下提供更強的推理能力(各使用案例提升達 10%),使其成為支援多步驟軟體開發流程的理想選擇。Cognition 使用新版 Claude 3.5 Sonnet 進行自主 AI 評估,在編碼、規劃和問題解決方面相較前版本有顯著改進。The Browser Company 在使用該模型自動化網路工作流程時注意到,Claude 3.5 Sonnet 的表現超越他們之前測試過的所有模型。
作為我們持續與外部專家合作的一部分,新版 Claude 3.5 Sonnet 模型的部署前聯合測試由美國 AI 安全研究所(US AISI)和英國安全研究所(UK AISI)進行。
我們也評估了升級後的 Claude 3.5 Sonnet 的災難性風險,發現我們負責任擴展政策中概述的 ASL-2 標準仍適用於此模型。
Claude 3.5 Haiku 將於本月晚些時候推出
Claude 3.5 Haiku 是我們最快模型的新一代產品。以相同的成本和與 Claude 3 Haiku 相近的速度,Claude 3.5 Haiku 在各項技能上都有所提升,在許多智能基準測試中甚至超越了我們上一代最大的模型 Claude 3 Opus。Claude 3.5 Haiku 在編碼任務上表現特別出色。例如,在 SWE-bench Verified 測試中得分達 40.6%,超越了許多使用公開可用的最先進模型的代理—包括原始的 Claude 3.5 Sonnet 和 GPT-4。
憑藉低延遲、改進的指令執行能力和更準確的工具使用,Claude 3.5 Haiku 非常適合面向用戶的產品、專門的子代理任務,以及從大量數據(如購買歷史、定價或庫存記錄)中生成個性化體驗。